Data Annotation vs. Data Labeling: A Technical Deep-Dive for Machine Learning Engineers and AI Teams
Understand the real difference between data annotation and data labeling, when to use each, how they impact AI model performance, and which approach your project actually needs. A complete guide by Interakt Techsol.

At a Glance
- In today's AI landscape, model architecture has largely standardized. The real competitive edge now lies in how well your training data is prepared and whether you are using the right approach for the right task.
- Confusing data annotation with data labeling is not just a terminology error; it leads directly to model failures, inaccurate predictions, and costly retraining cycles that delay production timelines.
- When your AI system is expected to perceive, reason, and operate reliably in real-world conditions, precision annotation is not a budget line item; it is the technical foundation your model depends on.
Every month, organizations across industries commit significant budgets to AI development, new model training runs, expanded infrastructure, and larger engineering teams. Yet the conversations in boardrooms and sprint planning sessions remain focused on the same variables: which model architecture, which cloud provider, and how many GPUs.
Very few of those conversations center on the factor that most reliably separates AI projects that succeed from those that fail: how the training data was prepared.
AI models are not shaped by their architecture alone. They are shaped by what they are taught and, more precisely, how their teachers (the data preparation teams) structured the information those models learned from. This is the point where treating data annotation and data labeling as interchangeable causes real, measurable harm to AI projects and the businesses that fund them.
These are not two names for the same process. They solve fundamentally different problems, serve different model types, and require different skills, tooling, and quality standards. Understanding which approach your project needs and why is among the most important technical decisions you will make before a single training epoch begins.
This guide covers both approaches in depth: what they are, where each belongs, how the choice between them shapes your model's real-world capability, and how to make the right decision for your specific AI initiative.
What Is Data Annotation?
Data annotation is the process of enriching raw data images, text, audio, video, and sensor streams with structured, contextual metadata that teaches machine learning models not just what objects or concepts exist, but where they are, how they behave, and how they relate to everything around them.
Annotation goes significantly beyond categorical tagging. It encodes the spatial, semantic, and temporal dimensions of data that allow models to develop genuine perceptual understanding, the kind that enables them to operate reliably in dynamic, real-world environments rather than controlled testing conditions.
Depending on the data modality and model objective, annotation takes different forms:
For computer vision and image-based models, annotation means:
- Drawing bounding boxes to precisely locate objects within an image frame
- Applying polygon and segmentation masks to define exact pixel-level boundaries of objects and regions
- Placing keypoints and skeletal landmarks to capture posture, geometry, and structural relationships
- Annotating depth and 3D orientation using cuboids for autonomous and spatial AI systems
- Marking scene attributes and contextual relationships between multiple objects in the same frame
For natural language processing and text-based models, annotation means:
- Named entity recognition (NER) identifies and classifies specific entities such as people, organisations, dates, and locations within text
- Intent and slot annotation mark what a user is trying to accomplish and the specific parameters within their request
- Coreference resolution tagging when different words or phrases across a document refer to the same underlying entity
- Relationship and dependency extraction encodes how entities are connected and how they influence each other
- Nuanced sentiment annotation capturing emotional tone with contextual detail beyond simple positive or negative classification
For video, audio, and sensor data, annotation means:
- Frame-level object tracking maintains the identity of individual objects as they move through a video sequence
- Temporal event detection marks the precise start and end timestamps of specific actions or occurrences
- Speaker diarisation and attribution, identifying which speaker produced which segments in multi-person recordings
- Multi-sensor fusion annotation correlating camera, radar, and LiDAR inputs into unified spatial representations
Together, these structures give your model a three-dimensional understanding of the world the spatial coordinates of where things are, the semantic meaning of what they represent, and the temporal context of how they change. Without annotation, a model can recognise that something exists. With it, a model can understand, reason, and act.
Use Cases Where Data Annotation Is Essential
The following applications all share a common requirement: the AI model must understand more than category membership. It must perceive structure, location, behaviour, and relationships. For these use cases, annotation is not an option; it is the technical prerequisite for the model to function as intended.
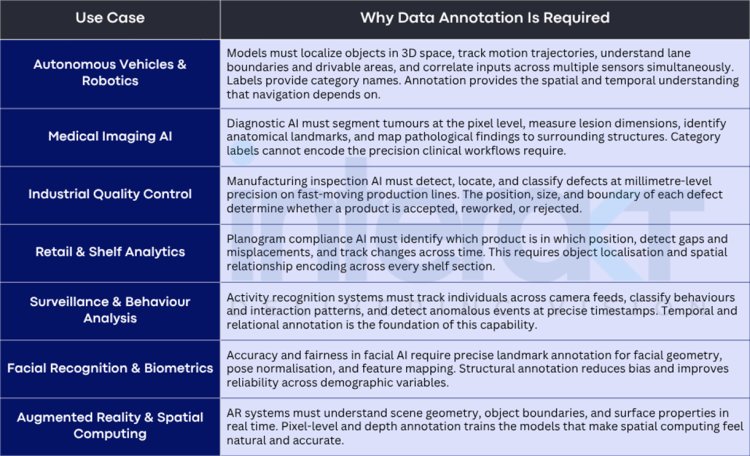
What these use cases share is that the consequence of getting the data preparation wrong is not marginal accuracy degradation; it is a system that cannot perform its core function. A detection model trained on labels does not detect with reduced accuracy. It does not detect at all.
What Is Data Labeling?
Data labeling is the process of assigning a predefined tag, category, or class to a unit of raw data, answering the fundamental question: "What category does this input belong to?"
Where annotation adds spatial, temporal, and semantic depth, labeling adds classification. The output is intentionally simple: a tag that tells a machine learning model which predefined bucket an input belongs to. This simplicity is the point, not a limitation, when the task the model must perform is classification.
A few examples of what well-executed data labeling produces:
- A product review assigned the label "positive"
- A support ticket tagged as "billing enquiry"
- An email classified as "spam"
- A transaction flagged as "high fraud risk"
- A document categorised as "purchase order"
Labels are:
- Categorical and predefined, chosen from a fixed taxonomy established before labeling begins
- Low-dimensional, a single value or a set of values from a defined list
- Structurally simple, they convey category membership without encoding position, boundaries, or relationships
Labeling sits at the beginning of the machine learning pipeline, during the dataset creation phase. It is designed to be fast and scalable, and when the model's learning objective is classification, speed and volume of correctly labeled data are the primary drivers of model quality.
Use Cases Where Data Labeling Is Enough
Data labeling is not a cheaper substitute for annotation; it is the technically appropriate approach when the model's objective is purely categorical. The following use cases are efficiently and correctly served by well-curated labeled datasets.

The Core Differences: Data Labeling vs. Data Annotation
The difference between data annotation and data labeling is not simply a matter of depth or cost it is a structural difference in what each approach teaches a model about the world. Understanding this across multiple dimensions helps organisations build the right data strategy from the start.
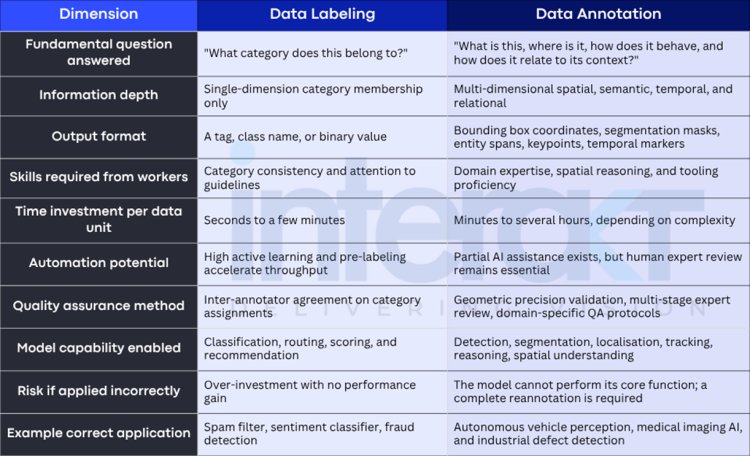
How the Difference Impacts Model Performance
Knowing what each approach is matters less than understanding what each approach does to the model that trains on it. The performance implications of annotation versus labeling are significant, concrete, and directly tied to your model's production behavior.
Labels teach models what things are. Annotations teach models how the world is structured.
With a labeled dataset, a model learns to distinguish between categories to draw a decision boundary between spam and legitimate email, between fraud and legitimate transactions, and between positive and negative sentiment. The model becomes skilled at pattern recognition within a categorical frame.
With an annotated dataset, a model learns the structure of its operating environment where objects exist within a scene, how they move over time, how their spatial relationships define context, and how semantic information is distributed across a document or utterance. The model develops perceptual capabilities that go significantly beyond category recognition.
This difference in training data structure directly produces differences in four key model properties:
Accuracy under real-world conditions
Annotation reduces ambiguity in the training signal. When a model learns from precise spatial and semantic metadata rather than just category names, it builds more robust internal representations. This translates to better performance on difficult inputs, partially occluded objects, unusual orientations, and the edge cases that categorical labeling rarely surfaces explicitly.
Robustness across distribution shifts
Models trained on richly annotated data generalise better when production inputs differ from the training distribution. A model that has learned the structural properties of objects, their geometry, how they appear from different angles, and how their appearance changes under different lighting adapts more reliably to new conditions than one trained on labels attached to whole images.
Explainability and auditability
Annotation-trained models can trace their outputs to spatial and semantic cues in the input. This makes their decisions more interpretable and easier to audit in regulated industries, including healthcare, financial services, and aviation.
Operational stability over time
Higher-quality, richer training data produce models that require less frequent retraining. Models trained on poorly prepared data, whether from wrong approach choice or poor annotation quality, degrade faster, generate more production errors, and require more intensive ongoing support.
Cost, Quality, and ROI: Data Labeling vs. Data Annotation
The per-unit cost of data labeling is significantly lower than annotation and this price difference is the most common reason teams choose the wrong approach. Understanding the full economics of each method requires looking beyond the per-item cost to the total cost of the decision.
Why annotation costs more upfront
The higher cost of annotation reflects genuine complexity. Producing a single high-quality annotated training record particularly for medical imaging, autonomous driving, or complex NLP requires:
- Specialist annotators with domain knowledge, not just general workers following basic guidelines
- More time per record minutes to hours rather than seconds
- Specialised tooling annotation platforms with modality-specific capabilities and precision controls
- Rigorous quality assurance inter-annotator agreement measurement, geometric precision validation, multi-stage review
- Detailed guideline development edge case protocols, calibration sessions, and ongoing team alignment
These are real costs. They reflect the complexity of the work being done.
Why cheap data produces expensive models
The cost comparison that matters is not labeling versus annotation per item it is the total project cost when the right versus the wrong approach is chosen.
An organization that labels 60,000 training images for a detection task at a fraction of the annotation cost will discover, several months into development, that the model cannot locate any of the objects it was trained to "detect." The labeled data provided category names. It provided no spatial coordinates, no bounding box ground truth, and no segmentation boundaries. The model trained on it can classify images, but cannot detect objects.
The recovery path requires reannotating all 60,000 images with correct annotation at annotation rates and costs. Added to this are the development costs already spent training and evaluating a model on incorrect data, the timeline delay, and the organisational cost of stakeholder trust.
The total cost of the wrong approach is always higher than the cost of the right approach.
Where annotation investment pays back
Beyond avoiding catastrophic project failure, annotation quality delivers measurable returns across the AI development lifecycle:
- Fewer retraining cycles, models trained on high-quality annotated data maintain performance longer, reducing the frequency and cost of retraining
- Reduced production errors, lower false positive and false negative rates, which means fewer errors reaching end users or downstream systems
- Regulatory defensibility in regulated industries, annotated and auditable training data, provides the documentation trail that compliance frameworks require
- Faster convergence, well-structured annotation helps models converge faster during training, reducing compute costs for the same performance level
The organisations that treat data annotation as a core AI investment rather than a cost to minimise consistently build models that perform better, require less ongoing maintenance, and generate measurable returns on the original development investment.
Data Labeling vs. Data Annotation: Choosing the Right Approach
The right choice is not about selecting the most comprehensive option or the most cost-efficient one. It is about matching the data preparation approach to what your model actually needs to learn.
Before committing to either approach, answer these four questions about your model's production requirements:
- What does my model need to output in production?
If it outputs a category, class, or score, labeling is likely the right approach. If it outputs spatial coordinates, boundaries, relationships, or temporal sequences, annotation is required.
- Does my model need to know where something is?
If the model must localise, detect, track, or spatially understand anything in its input, annotation is non-negotiable. No architecture or technique compensates for the absence of spatial ground truth in training data.
- Will my model's output directly influence high-stakes decisions?
If model errors carry financial risk, patient safety implications, or regulatory consequences, both the approach and the quality standard for that approach must reflect that weight. High-stakes applications require annotation, and require it to be executed at a high standard.
- Does the relationship between elements in my data matter?
If context, position, or interaction between elements affects the correct output, annotation is required to encode those relationships. Labeling treats each element independently; it cannot represent relational structure.
If your answers point clearly toward annotation, choose a partner with genuine domain expertise in your specific modality, a rigorous multi-stage quality process, and the operational scale to maintain annotation quality as your dataset grows.
If your answers point toward labeling, invest in guidelines, consistency protocols, and quality sampling. Well-executed labeling at scale is highly effective for classification tasks, and the difference between good and poor labeling quality compounds directly into model performance.
If your answers are mixed, which is common for real-world AI systems of any complexity, build a data strategy that applies the right approach to each component. Classification tasks within a larger system get labeled. Detection and reasoning tasks get annotated. A clear data strategy at the outset prevents the most common and costly form of this confusion.
At Interakt Techsol, every data preparation engagement begins with a strategy session that maps your model's production requirements to the right approach for each data type before annotation or labeling work begins. This ensures that your data budget generates maximum return on model performance.
Data is AI's Operating System
There is a lasting tendency in AI development to frame the model as the product and the data as a preparatory step. The outcomes of AI projects consistently tell a different story.
The model is the mechanism. Data is the operating system it runs on. What the model can do and how reliably it does it is bounded by what its training data taught it to understand. No architecture improvement, no hyperparameter tuning, no increase in compute changes that fundamental constraint.
Data labeling and data annotation are not competing philosophies or budget tiers. They are purpose-built tools for different objectives. Labeling gives models a categorical understanding of the ability to sort, classify, route, and score. Annotation gives models the ability to see, reason, and act in the structured complexity of the real world.
Choosing the right approach requires clarity about what you need your model to do, not in a testing environment, not in a demo, but in production, at scale, in conditions you did not fully anticipate when you began the project.
That clarity, applied at the start of a data preparation project, is the decision that determines whether your AI system performs reliably or fails unpredictably. Whether your investment compounds over time or requires constant rebuilding. Whether your model is a competitive capability or an ongoing liability.
Make that decision deliberately. Build your data foundation accordingly.
FAQ
What is the key difference between data annotation and data labeling?
Data labeling assigns a category tag to data, answering "what category does this belong to?" Data annotation adds rich contextual metadata answering "what is this, where is it, how does it behave, and how does it relate to its environment?" The choice between them is determined by what the model needs to produce in production.
When should I use data annotation instead of data labeling?
Use data annotation when your model needs to detect, localise, track, segment, or structurally understand anything in its input. This includes computer vision, autonomous systems, medical imaging, and NLP applications requiring named entity recognition, relationship extraction, or coreference resolution.
Is data labeling cheaper than data annotation?
Per data unit, labeling typically costs significantly less than annotation, reflecting the difference in skill requirements, time per record, tooling complexity, and QA rigor. However, applying labeling to a task that requires annotation does not save money; it results in a model that cannot perform its intended function, requiring full reannotation and retraining at additional cost.
Can data labeling and annotation be used together in the same project?
Yes, and most real-world AI systems of meaningful complexity require both. Different components of a system may have different data requirements. A strategy review at the start of the project identifies which components need which approach, ensuring every rupee of data spend is applied correctly.
How does data annotation improve model performance?
Annotation improves model accuracy by reducing ambiguity in the training signal, helps models generalise better under distribution shift, improves robustness on edge cases, and enables explainability by linking model decisions to specific spatial and semantic cues in the training data.
What types of data can be annotated?
Data annotation applies across all major modalities: images, video, text, audio, LiDAR point clouds, and multi-sensor fusion datasets. The annotation techniques and tooling differ by modality, but the principle of adding structured contextual metadata to raw data applies consistently across all of them.












